
مقدمه
یکی از مهمترین حوزههای تحقیقات و توسعه در حوزه هوش مصنوعی (AI) در سالهای اخیر، حوزه پردازش زبان طبیعی بوده است. این علم موجب میشود کامپیوترها به یک قدرت انقلابی در درک زبان انسان، زبانهای برنامهنویسی و حتی رشتههای شیمیایی و زیستی مثل DNA و ساختار پروتئین که شبیه به زبان هستند برسند. مدلهای جدید NLP (Natural Language Processing) هر فصل با رشد و تغییرات ثابتی که داشته منتشر شده و با استفاده از قابلیتهای انتزاعی مختلف، رویههای آموزشی متفاوت و دیتاستهای گوناگون آموزش داده میشوند.
۱. پردازش زبان طبیعی (NLP) چیست؟
پردازش زبان طبیعی، قواعد ساخت ماشینهایی است که بتوانند زبان انسان یا دادههایی که شبیه زبان انسان هستند را به شیوهای که نوشته، گفته و سازماندهی میشوند بفهمند و دستکاری کنند.
یادگیری انتقالی یا Transfer learning روش رایجی برای شروع تسکهای رایج یادگیری عمیق مثل بینایی ماشین و پردازش زبان طبیعی (NLP) هستند. در این روش، مدل، قبل از اینکه در کار دیگری تنظیم شود، ابتدا روی تسکی که اطلاعاتی غنی دارد پیشآموزش داده میشود. روشها، متدها و راههای مختلفی با میزان متفاوتی از تاثیرگذاری در یادگیری انتقالی پدید آمدهاند.
در این مقاله درباره مدلهای پیشآموزشی و ۷ مورد از مدلهای پیشگام NLP که به عملکرد خوبی در معیارهای مختلف رسیدهاند و در فضای آکادمیک و صنعتی از آنها استفاده میشود، میپردازیم.
۲. مدلهای پیشآموزشی پردازش زبان طبیعی
فرض کنید در حال کار روی یادگیری ماشین یا همان ماشین لرنینگ هستیم و نیاز به مدلهای از پیشآموزش داده شدهای داریم که تسکهای مشابه را آموزش دیده باشند و بتوانیم آنها را به تسکهایی که در حال کار روی آنها هستیم اعمال کنیم. به این ترتیب نیازی نیست که مدلی را خودمان از صفر بسازیم.
مدلهای پیشآموزشی به مدلهایی اشاره دارد که روی حجم بزرگی از دادههای متنی آموزش داده شدهاند تا الگوهای زیربنایی آنها و ساختار زبان انسان را درک کنند.
سه کاربرد اصلی مدلهای پیشآموزشی در انتقال آموزش، استخراج ویژگیها و طبقهبندی مشاهده میشوند که در انتقال آموزش برای اپلیکیشنهای مختلف شامل ترجمه ماشینی، تحلیل احساسات، خلاصهسازی متن، تشخیص گفتار و پاسخ به سوال به کار میروند.
۳. هفت مورد از قویترین مدلهای پیشآموزشی در پردازش زبان طبیعی
در این بخش به بررسی ۷ مورد از قویترین مدلهای زبانی بزرگ برای تسکهای NLP که در مقالات اخیر منتشر شدهاند میپردازیم.
۳.۱ GPT-4 (Generative Pre-trained Transformer 4)
GPT-4 در ۱۴ مارس ۲۰۲۳ توسط اوپن ایآی (OpenAI) به صورت عمومی همراه با ChatGPT ارائه شد که برای پیشبینی توکن بعدی سند متنی، با استفاده از دادههای در دسترس عمومی و دادههای مجاز تامینکنندههای شخص ثالث آموزش داده شده بود. بعدها این مدل با استفاده از یادگیری تقویتی از بازخورد انسان (Reinforcement Learning from Human Feedback) به شکل بهتری تنظیم شد. GPT-4 دستوراتی متشکل از متن و تصویر را میگیرد. این مدل با وجود قابلیتهایی که دارد نسبت به مدلهای قدیمی GPT دارای محدودیتهایی نیز هست که باعث شده کاملاً قابل اعتماد نباشد.

۳.۲ GPT-3 (Generative Pre-trained Transformer 3)
GPT-3 که در سال ۲۰۲۰ توسط اوپن ایآی منتشر شد، یک مدل زبانی بزرگ و سومین مدل از سری مدلهای اصلی GPT بود. این مدل زبانی تنها یک مدل تبدیلی است که فقط نقش دیکدر (Decoder) را در شبکه عصبی عمیق دارد که از میزان توجه به محل تکرار و نیز معماری مبتنی بر کانولوشن استفاده میکند.
وقتی این دادهها را به GPT-3 دادیم، زبان را بررسی کرده و از یک پیشبینیکننده متن استفاده میکند تا شبیهترین خروجی را تولید کند. این مدل حتی بدون تنظیمات و آموزشهای اضافی هم میتواند خروجیهای با کیفیتی تولید کند که شبیه همان چیزی هستند که انسانها تولید میکنند. GPT-3 حوزه پردازش زبان طبیعی را دچار انقلاب کرده است. این مدل با ۱۷۵ میلیارد پارامتر از اوایل سال ۲۰۲۱ تا به حال بزرگترین شبکه عصبی تولید شده است. البته برخی جزئیات فنی آن مثل سایز مدل را اوپن ایآی فاش نکرده است.
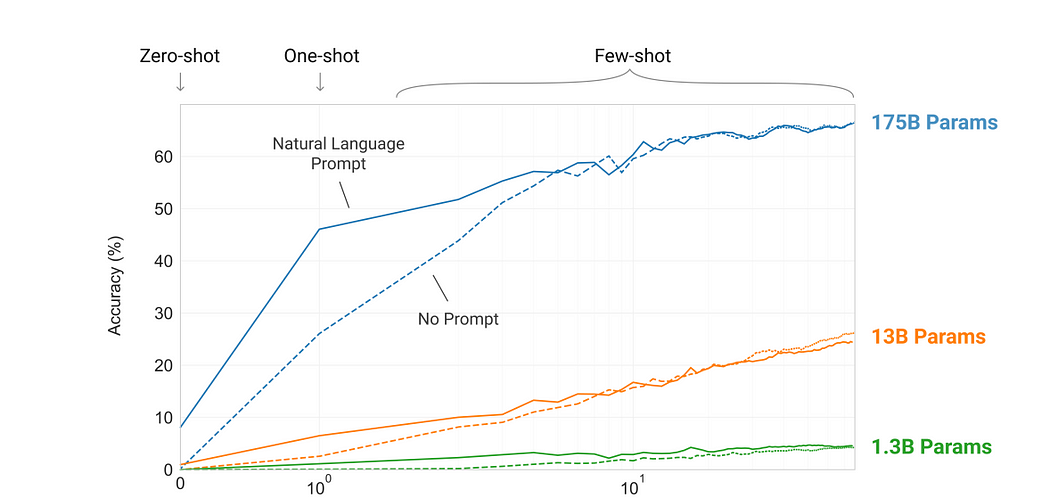
مدلهای بزرگتر باعث کاربرد مؤثر اطلاعات درونزمینهای میشوند.
۳.۳ T5 (تبدیلکننده انتقال متن به متن)
مدل تبدیلکننده T5 در سال ۲۰۲۰ توسط گوگل ایآی منتشر شد و نام آن مخفف کلمه تبدیلکننده انتقال متن به متن بود. مهمترین مشکلی که T5 بر آن تمرکز داشت، نبود مطالعات سیستمایک در مقایسه با بهترین عملکردها در حوزه NLP بود.
T5 یک معماری مبتنی بر تبدیلکننده دارد که از روش متن به متن استفاده میکند. تسکهایی مثل طبقهبندی، قابل قبول بودن از نظر زبانی، خلاصه کردن متن، ترجمه و پاسخدهی به سوالات به عنوان ورودی مدل برای آموزش و تولید متن هدف استفاده میشوند. این امکان استفاده از مدلهای مشابه، تابع جزا، فراپارامترها و غیره را در مجموعه متنوعی از وظایف امکانپذیر میکند.
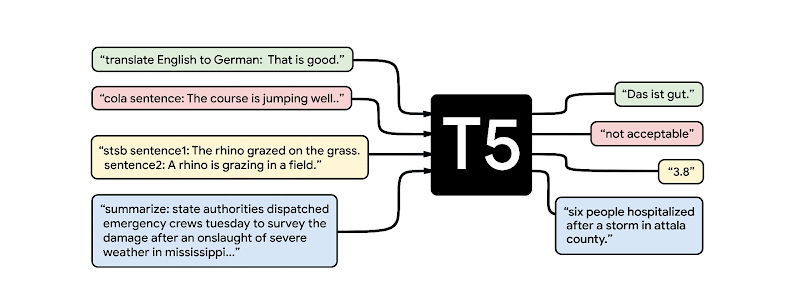
تسکهای پردازش متن
۳.۴ ELMO (تعبیههای مدلهای زبانی)
ELMO در سال ۲۰۱۹ بزرگترین توسعهای بود که توسط AllenNLP انجام شد. ELMO راهی برای نمایش کلمات در بردار یا تعبیههاست. از یک مدل زبانی دو جهته استفاده میکند که وابستگی بین کلمات را در هر دو جهت نشان میدهد.
ELMO برخلاف سایر روشهای قدیمی تعبیهسازی نظیر word2vec و GLoVe، اختصاص داده شده به یک توکن یا کلمه است که در واقع تابعی از کل جمله حاوی آن کلمه میباشد. در نتیجه، یک کلمه میتواند بردارهای کلمه متفاوتی در زمینههای مختلف داشته باشد. ELMO نتایج قدرتمندی در NLP مانند تحلیل احساسات، طبقهبندی متن و پاسخ به سوالات نشان داده است.
۳.۵ RoBERTa (رویکرد بهینهشده BERT)
یکی از انواع BERT، RoBERTa در سال ۲۰۱۹ توسط محققان فیسبوک ارائه شد. BERT نیز همانند RoBERTa یک مدل زبانی مبتنی بر تبدیلکننده است که برای پردازش رشتههای ورودی و تولید نمایشهایی از کلمات در غالب جمله از توجه به خود (self-attention) استفاده میکند.
RoBERTa از این جهت با BERT متفاوت است که روی یک دیتاست بزرگتر و با استفاده از روشهای آموزشی کارآمدتری آموزش داده شده است. دیتاستی که برای آموزش آن به کار رفته ده برابر بزرگتر از دیتاست به کار رفته برای BERT بوده است.
مشخص شده که RoBERTa در انجام انواع وظایف پردازش زبان طبیعی از جمله ترجمه، طبقهبندی متن و پاسخ به سوالات بهتر از BERT و سایر مدلهای پیشرفته (SOTA) عمل میکند.
۳.۶ ALBERT (نمایش رمزگذاری دو جهته سبک از تبدیلکنندهها)
در سال ۲۰۱۸ محققان گوگل ایآی، BERT را ارائه کردند که یک تحول انقلابی در زمینه NLP بود. بعدها در سال ۲۰۱۹ مدل ALBERT را برای یادگیری خود-نظارتی زبان منتشر کردند که معماری مشابه BERT داشت.
هدف اصلی این مدل بهبود آموزش و نتایج معماری BERT با استفاده از تکنیکهای مختلف نظیر فاکتورسازی ماتریس، یکپارچهسازی اشتراکگذاری پارامتر و کاهش پیچیدگی جملات بود.
۳.۷ BERT (نمایش رمزگذار دو جهته از تبدیلکنندهها)
BERT در سال ۲۰۱۸ توسط گوگل و براساس مدل تبدیلکنندهها ایجاد شد که در مقالهای در سال ۲۰۱۷ توضیح داده شده بود. BERT مدلی است که به مقدار قابل توجهی پیشآموزش دیده و قابلیت درک اطلاعات متنی را به صورت دو طرفه دارد. این مدل از چندین لایه خود-توجهی (self-attention) و شبکه عصبی پیشخور (feed-forward neural networks) تشکیل شده است.
همچنین برای گرفتن اطلاعات مبتنی بر کل معانی قبلی یا بعدی و نیز زیر-کلمههای یک جمله از روش دو طرفه استفاده میکند و با ۳.۳ میلیارد کلمه آموزش دیده است.
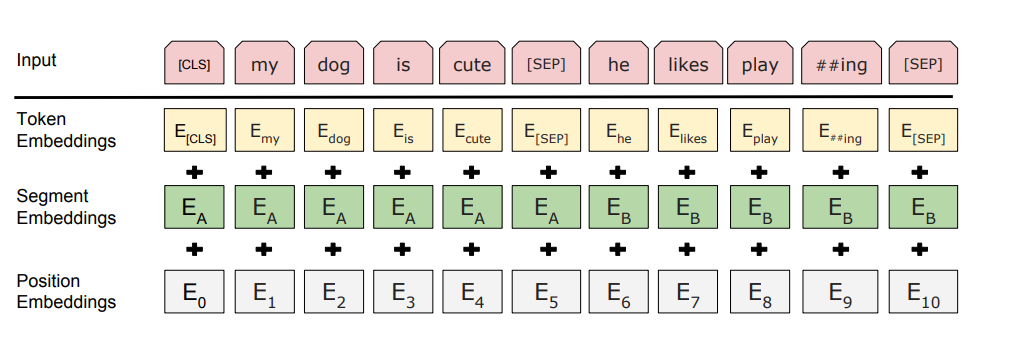
نمایش ورودیهای BERT:
۴. نقاط ضعف و قوت هر یک از این ۷ مدل
در این بخش به مقایسه نقاط ضعف و قوت هر یک از ۷ مدل پیشرفته زبان بزرگ پرداخته میشود تا بتوانید بهترین مدل را بر اساس نیازهای خود انتخاب کنید.
| مدل | نقاط قوت | نقاط ضعف |
|---|---|---|
| GPT-4 |
|
|
| GPT-3 |
|
|
| T5 |
|
|
| ELMO |
|
|
| RoBERTa |
|
|
| ALBERT |
|
|
| BERT |
|
|
جدول بالا نقاط ضعف و قوت هر یک از مدلهای مورد بررسی را نشان میدهد. انتخاب مدل مناسب بستگی به نیازهای خاص پروژه شما، منابع در دسترس و تسکهای مورد نظر دارد. به طور کلی، مدلهای بزرگتر مانند GPT-4 و GPT-3 قدرت تولید بالاتری دارند اما هزینههای محاسباتی و منابع بیشتری نیز نیازمندند. مدلهایی مانند ALBERT با کاهش پارامترها، متعادلسازی بین دقت و کارایی را ارائه میدهند، در حالی که مدلهای دیگری مانند ELMO و BERT در تسکهای خاص عملکرد بهتری دارند.
۵. نتیجهگیری
پردازش زبان طبیعی (NLP) یکی از حوزههای تحقیقاتی در حال توسعه در هوش مصنوعی (AI) است که کاربردهای زیادی نظیر ترجمه، خلاصهسازی، تولید متن و تحلیل جمله را دارد. در صنعت نیز از مدلهای NLP برای تشخیص کلاهبرداریهای بیمهای، بهینهسازی نگهداری و تعمیرات هواپیما، تجزیه و تحلیل احساسات مشتریان و غیره استفاده میشود.
مدلهای پیشآموزشی سریع بوده و راهی مؤثر برای ساخت اپلیکیشنهای AI هستند، اما همیشه هم تضمین نمیشود که برای تسکهای مختلف، بازده مشابهی داشته باشند.



بدون نظر